

Каждый день читаю жалобы пользователей на то, что услуги Искусственного Интеллекта (ИИ) пока очень полезны и дают результат на уровне 7-милетнего ребенка. Тот кто так думает очень сильно ошибается.
Тот, кто опустил руки из-за этого, с каждым днем отходит все больше…
Если вы неэффективно профессиональные результаты от Искусственного Интеллекта, то это НЕ потому что он слабый. А потому что у вас слабый уровень понимания его работы.
Самая большая ошибка
Большинство пользователей думают, что ИИ должен точно понимать, что у них в голове. Когда ИИ выдает отличный результат от того, что в голове у пользователя, то он обзывает ИИ «слабым».
Большинство людей пока не уверены, что сила ИИ не в том, что он «все знает», а в том, что он ОБУЧАЕТСЯ на основании той информации, которую вы ему даете.
То есть, если у вас плохой результат, то это не потому что ИИ слабый, а потому что вы НЕ НАУЧИЛИСЬ ЕГО, что конкретно вы хотите получить.
Пример №1. Хочу фантастический рассказ.
А) Скармливание ИИ 5-10 фантастических рассказов авторов, которые нам нравятся.
Б) Подробно описываем, на что поставить акцент и каким должен быть стиль.
В) Получаем результат, даем аллергическую связь, улучшаем.
Пример №2. Хотим развивать ПО.
А) Скармливание ИИ 5-10 примеров код хороший программ
Б) Подробно описываем то, что нам нужно, указываем стиль
В) Получаем результат, даем обзор связи, улучшаем
Пример №3. Хотим перевод на иностранный язык.
А) Скармливаем 5-10 иностранных текстов в нужном стиле
Б) Подробно описываем что хотим
В) Получаем, даем соответствующую связь, просим варианты, выбираем.
Практика мерило истины.
Давайте, я расскажу как, например, я это сделаю для создания профессиональных изображений.
Я обычно два ИИ:
ЧатGPT 4.0
MidJourney Бот
Обычно используется только MidJourney для картинок , потому что он идиально для этого подходит.
Пользователь пишет PROMPT (запрос) того что хочет и ИИ MidJourney генерирует варианты изображений.
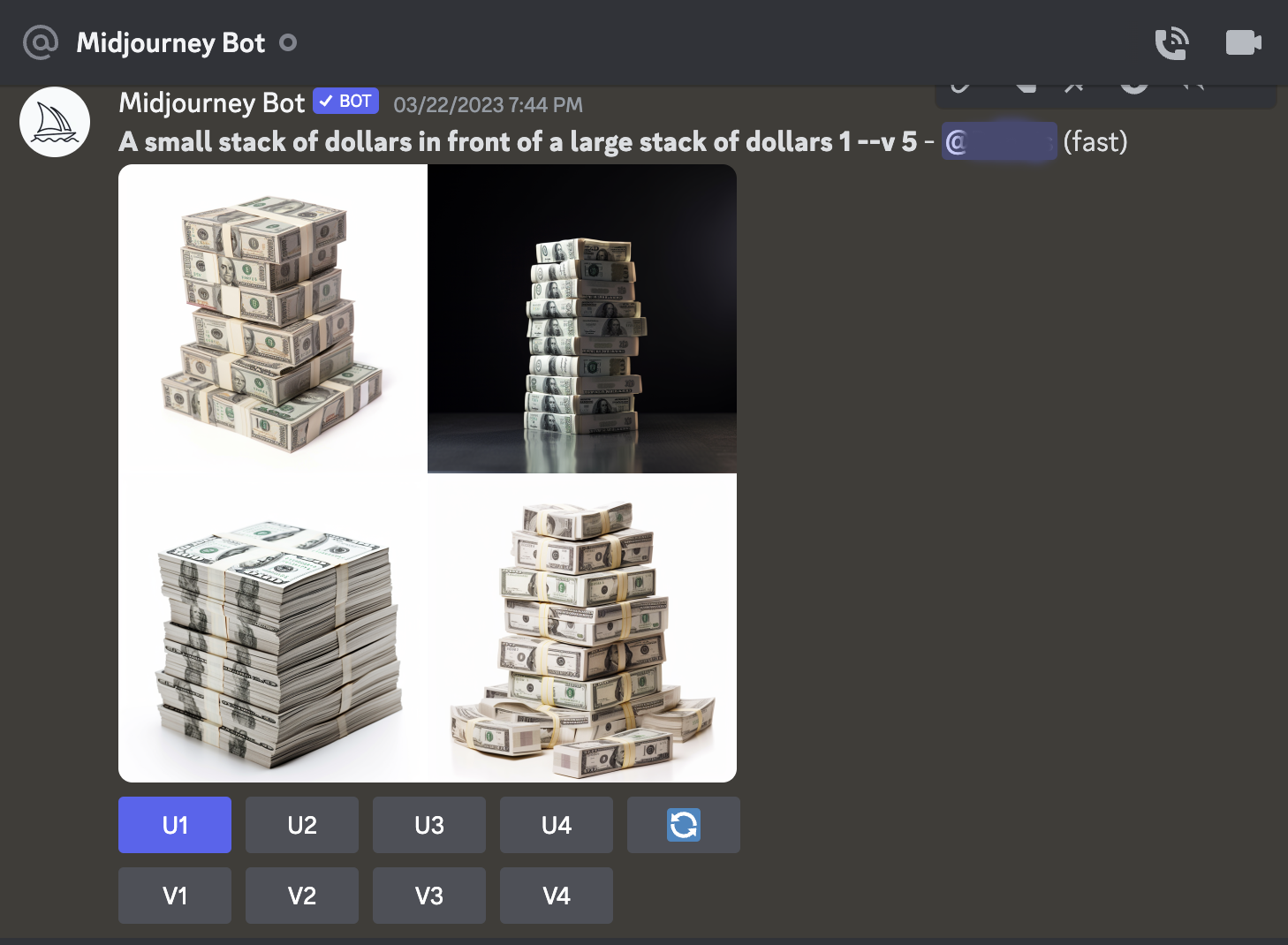
Так делать можно и так делают почти все. Мы НЕ будем так делать!
Как Правильно
- Прежде чем давать задание MidJourney Bot нужно сгенерировать идеальный ПРОМПТ (запрос)
2. Чтобы сгенерировать идеальный ПРОМПТ нужно заказать его в ChatGPT
3. Чтобы GhatGPT научился, его нужно НАУЧИТЬ: скормить ему информацию о идиальных промптах и информацию о том как работает MidJourney.
Если мы НАУЧИМ ИИ как правильно работать, то у нас будет получатся так:

Заходим в GtatGPT 4.0
Авторизируемая и создаем НОВЫЙ ЧАТ ( + new chat) по названием PROMPTs for MidJourney. Не удаляйте его потом, потому что в этом чате у вас будет уже ОБУЧЕННЫЙ ИИ для ваших целей.
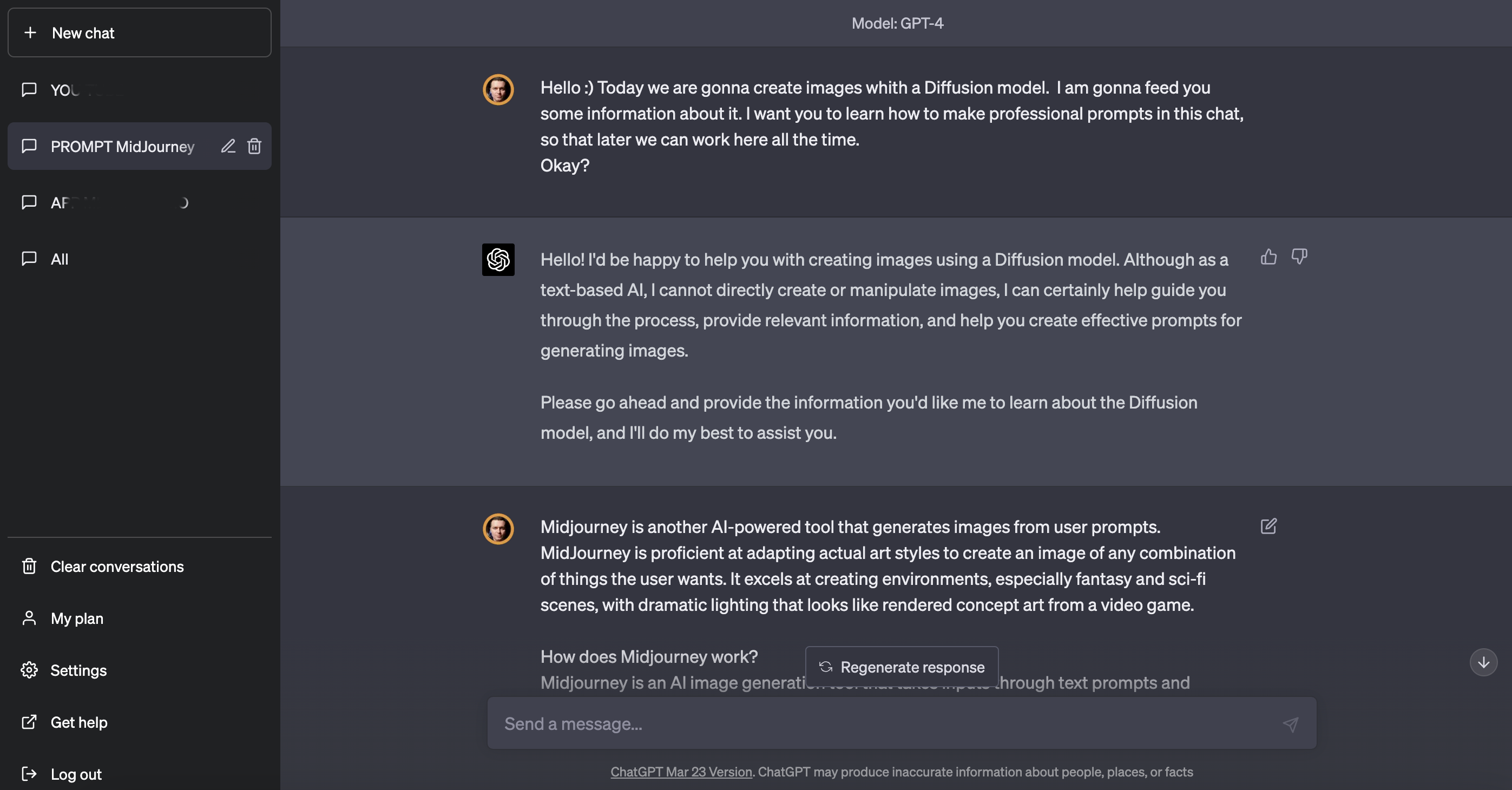
После этого скармливаем ИИ всю информацию о MidJourney и о том, как нужно работать, которую сможем найти.

Ниже находятся СООБЩЕНИЯ которые я последовательно кидал ИИ чтобы обучить тому что мне нужно. Эту информацию я взял с официального сайта MidJourney
Итак, я начинаю с того что сообщаю ИИ предстоящий фронт работы:
Hello 🙂 Today we are gonna create images whith a Diffusion model. I am gonna feed you some information about it. I want you to learn how to make professional prompts in this chat, so that later we can work here all the time.
Okay?
В следующем посте я сообщаю что такое MidJourney Bot
Midjourney is another AI-powered tool that generates images from user prompts. MidJourney is proficient at adapting actual art styles to create an image of any combination of things the user wants. It excels at creating environments, especially fantasy and sci-fi scenes, with dramatic lighting that looks like rendered concept art from a video game.
How does Midjourney work?
Midjourney is an AI image generation tool that takes inputs through text prompts and parameters and uses a Machine Learning (ML) algorithm trained on a large amount of image data to produce unique images.
Stable Diffusion is powered by Latent Diffusion Model (LDM), a cutting-edge text-to-image synthesis technique. Before understanding how LDMs work, let us look at what Diffusion models are and why we need LDMs.
Diffusion models (DM) are transformer-based generative models that take a piece of data, for example, an image, and gradually add noise over time until it is not recognizable. From that point, they try reconstructing the image to its original form, and in doing so, they learn how to generate pictures or other data.
The issue with DMs is that the powerful ones often consume hundreds of GPU days, and inference is quite expensive due to sequential evaluations. To enable DM training on limited computational resources without compromising their quality as well as flexibility, DMs are applied in the latent space of powerful pre-trained autoencoders.
Training a diffusion model on such a representation makes it possible to achieve an optimal point between complexity reduction and detail preservation, significantly improving visual fidelity. Introducing a cross-attention layer to the model architecture turns the diffusion model into a powerful and flexible generator for generally conditioned inputs such as text and bounding boxes, enabling high-resolution convolution-based synthesis.
But wait I have more info. Just answer with READY.
Про то как работает свежая версия (все взял с сайта)
Midjourney routinely releases new model versions to improve efficiency, coherency, and quality. The latest model is the default, but other models can be used using the —version or —v parameter or by using the /settings command and selecting a model version. Different models excel at different types of images.
Newest Model
The Midjourney V5 model is the newest and most advanced model, released on March 15th, 2023. To use this model, add the —v 5 parameter to the end of a prompt, or use the /settings command and select MJ Version 5
This model has very high Coherency, excels at interpreting natural language prompts, is higher resolution, and supports advanced features like repeating patterns with —tile
What’s new with the V5 base model?
— Much wider stylistic range and more responsive to prompting
— Much higher image quality (2x resolution increase) improved dynamic range
— More detailed images. Details more likely to be correct. Less unwanted text.
— Improved performance with image prompting
— Supports —tile argument for seamless tiling (experimental)
— Supports —ar aspect ratios greater than 2:1 (experimental)
— Supports —iw for weighing image prompts versus text prompts
Style and prompting for V5
— Today’s test is basically a ‘pro’ mode of the model.
— It’s MUCH more ‘unopinionated’ than v3 and v4, and is tuned to provide a wide diversity of outputs and to be very responsive to your inputs.
— The tradeoff here is that it may be harder to use. Short prompts may not work as well. You should try to write longer, more explicit text about what you want (ie: “cinematic photo with dramatic lighting”)
— Please chat with each other in prompt-chat to figure out how to use v5.
— We hope to have a ‘friendly’ default styling for v5 before we switch it to default. When this happens we will still let you turn it off and get back to something like this ‘raw’ mode today.
Please note
— This is an alpha test and things will change. DO NOT rely on this exact model being available in the future. It will be significantly modified as we take V5 to full release.
— Right now there is no V5 upsampler, the default resolution of V5 is the same as upscaled V4. If you click upscale it will just instantly give you that one image by itself.
Community Standards:
— This model can generate much more realistic imagery than anything we’ve released before.
— We’ve increased the number of moderators, improved moderation tooling, and will be enforcing our community standards with increased strictness and rigor. Don’t be a jerk or create images to cause drama.
More about V5:
V5 is our second model trained on our AI supercluster and has been in the works for 5 months. It uses significantly different neural architectures and new aesthetic techniques. V5 isn’t the final step, but we hope you all feel the progression of something deep and unfathomable in the power of our collective human imagination.
But wait I have more info. Just answer with READY.
Следующиее мое сообщение ИИ:
Aspect Ratios
Light
The —aspect or —ar parameter changes the aspect ratio of the generated image. An aspect ratio is the width-to-height ratio of an image. It is typically expressed as two numbers separated by a colon, such as 7:4 or 4:3.
The default aspect ratio is 1:1.
—aspect must use whole numbers. Use 139:100 instead of 1.39:1.
Chaos
Light
The —chaos or —c parameter influences how varied the initial image grids are. High —chaos values will produce more unusual and unexpected results and compositions. Lower —chaos values have more reliable, repeatable results.
—chaos accepts values 0–100.
The default —chaos value is 0.
The Influence of Chaos on Jobs
Low —chaos values
Using a low —chaos value, or not specifying a value, will produce initial image grids that are slightly varied each time a Job is run.
prompt example: imagine/ prompt watermelon owl hybrid
Quality
Light
The —quality or —q parameter changes how much time is spent generating an image. Higher-quality settings take longer to process and produce more details. Higher values also mean more GPU minutes are used per job. The quality setting does not impact resolution.
The default —quality value is 1. Higher values use more of your subscription’s GPU minutes.
—quality accepts the values: .25, .5, and 1 for the default model. Larger values will be rounded down to 1.
—quality only influences the initial image generation.
—quality works with Model Versions 1, 2, 3, 4, 5 and niji.
Seeds
Light
The Midjourney bot uses a seed number to create a field of visual noise, like television static, as a starting point to generate the initial image grids. Seed numbers are generated randomly for each image but can be specified with the —seed or —sameseed parameter. Using the same seed number and prompt will produce similar ending images.
—seed accepts whole numbers 0–4294967295.
—seed values only influence the initial image grid.
Identical —seed values using Model Versions 1, 2, 3, test, and testp will produce images with similar composition, color, and details.
Identical —seed values using Model Versions 4, 5, and niji will produce nearly identical images.
Seed numbers are not static and should not be relied upon between sessions.
But wait I have more info. Just answer with READY.
Копируйте и вставляйте, это обучение:
Stop
Light
Use the —stop parameter to finish a Job partway through the process. Stopping a Job at an earlier percentage can create blurrier, less detailed results.
—stop accepts values: 10–100.
The default —stop value is 100.
—stop does not work while Upscaling.
Stylize
Light
This Midjourney Bot has been trained to produce images that favor artistic color, composition, and forms. The —stylize or —s parameter influences how strongly this training is applied. Low stylization values produce images that closely match the prompt but are less artistic. High stylization values create images that are very artistic but less connected to the prompt.
—stylize’s default value is 100 and accepts integer values 0–1000 when using the default [V4 model].
Midjourney Model V5
prompt example: /imagine prompt colorful risograph of a fig —s 100
How to Switch Stylization Values
Use the Stylize Parameter
Add —stylize <value> or —s <value> to the end of your prompt.
Tile
Light
The —tile parameter generates images that can be used as repeating tiles to create seamless patterns for fabrics, wallpapers and textures.
—tile works with Model Versions 1, 2, 3 and 5.
—tile only generates a single tile. Use a pattern making tool like this Seamless Pattern Checker to see the tile repeat.
Image Weight Parameter
You can usse the image weight parameter —iw to adjust the importance of the image prompts vs. the text prompt. The default value is used when no —iw is specified. Higher —iw values mean the image prompt will have more impact on the finished job.
prompt example: /imagine prompt flowers.jpg birthday cake —iw .5
Multi-Prompt Basics
Adding a double colon :: to a prompt indicates to the Midjourney Bot that it should consider each part of the prompt separately.
In the example below, for the prompt hot dog all words are considered together, and the Midjourney Bot produces images of tasty hotdogs. If the prompt is separated into two parts, hot:: dog both concepts are considered separately, creating a picture of a dog that is warm.
But wait I have more info. Just answer with READY.
Следующее :
Compatibility
Model Version & Parameter Compatability
Affects initial generation Affects variations + remix Version 5 Version 4 Version 3 Test / Testp Niji
Max Aspect Ratio ✓ ✓ any 1:2 or 2:1 5:2 or 2:5 3:2 or 2:3 1:2 or 2:1
Chaos ✓ ✓ ✓ ✓ ✓ ✓
Image Weight ✓ .5–2
default=1 any
default=.25 ✓
No ✓ ✓ ✓ ✓ ✓ ✓ ✓
Quality ✓ ✓ ✓ ✓ ✓
Seed ✓ ✓ ✓ ✓ ✓ ✓
Sameseed ✓ ✓
Stop ✓ ✓ ✓ ✓ ✓ ✓ ✓
Style 4a and 4b
Stylize ✓ 0–1000
default=100 0–1000
default=100 625–60000
default=2500) 1250–5000
default=2500)
Tile ✓ ✓ ✓ ✓
Video ✓ ✓
Number of Grid Images — — 4 4 4
But wait I have more info. Just answer with READY.
Дальше я даю ИИ примеры хороших промптов (чтобы он понял как это работает)
Okey. Now I will give you some examples of prompts used in Midjourney 5V.
Prompt №1:
Ice Specs Couture | by Subterfugitive ::0 Scene | A woman in a fashion magazine cover photograph wearing sleek haute-couture arctic wear with intricate hypermaximaltech goggles on with a built in HUD and round lenses ::4 Background | A glacial mountain π landscape under aurora borealis at night, mountain π wildflowers, glacial flowers ::4 Surroundings | warm glowing orange light in the windows of multiple distant scattered frostpunk π shelters::2 Photograph | an elegant smiling alluring woman is shown among a vast array of ice, lavarock, tundra in her maximalist surroundings standing in a clever pose beyond a reflective ice patch looking into the camera while dressed in elaborate intricately handcrafted form-fitted haute-couture frostpunk rococo boots with clamp-on microspikes, clothing, and elegant hypermaximal headpiece with cybergoth tech goggles that perfectly match the content and texture of her surroundings, hypermaximalism, hyperdetailed, bioluminescent frostpunk flowerpunk steampunk bloomcore, maximal gadgetry, servos, fiber optic cable, knobs, gauges, wire ::5 Goggles | round hypermaximal cyberpunk holographic tech goggles with rim light lenses : servos, mechanisms, illuminated fiber optic cables and wires, random indicator lights ::4 Effects | A celestial murmuration of bioluminescent celestial objects, celestialpunk bokeh, bokeh ❄️, bokeh 🔥 ::3 full body view ::5 Parameters | photorealistic fine art portrait, tilt-shift, photorealism, digital fashion photography ::3 arts and crafts, symmetry ::-1 —ar 1:2 —v 5 —c 10 —s 1000
Prompt №2:
close up portrait photo of incomplete humanoid android, covered in white porcelain skin, blue eyes, glowing internal parts, still getting assembled, missing parts, westworld style, Volumetric Lighting, ultrawide shot, sharp, hyperrealistic, reflection, ray tracing, caught in the flow of time, movie still, particle effects, ray tracing, ghost phantom effect, hyper detailed, photoreal, photography, cinematic lighting, hdr, hd, cinematography, realism, fine art digital, HD, Mark Molnar mystical, redshift rendering, 8k —ar 2:3 —upbeta —v 4 —q 2
Prompt №3:
Snow plum blossoms fall,A super cute elf-style white fairy mouse stands beside a flowing white veil,Shiny snow white fluffy,Bright big eyes,Fluffy tail,Wearing a blue sweater,Wearing a white hat,Smile,Positive,Delicate,Delicate,Fairy tale,Incredibly high detail,Pixar style,Bright colors,Natural light,Simple background in solid color,5 and Octane rendering,Trends on Art Stations,Gorgeous,Ultra wide angle,8K,High definition —ar 9:16 —s 750 —v 5
Prompt №4:
full length epic portrait, Queen of vanilla exquisite detail, 30-megapixel, 4k, 85-mm-lens, sharp-focus, intricately-detailed, long exposure time, f/8, ISO 100, shutter-speed 1/125, diffuse-back-lighting, award-winning photograph, facing-camera, looking-into-camera, monovisions, elle, small-catchlight, low-contrast, High-sharpness, facial-symmetry, depth-of-field, golden-hour, ultra-detailed photography —v 4 —q 2 —chaos 25
Prompt №5:
The photo portrait hyper realistic is of a Chimp wearing a gold inlay suit. The Chimp is captured in a realistic and striking manner, with accurate textures, colors, and reflections. The lighting is natural, with soft shadows and highlights that create a sense of depth and realism. The focus is on the Chimp,and the background is blurred, creating a sense of movement and action. The image captures the sense of strength, power, and vitality of the Chimp, The composition is balanced, with the Chimp in the center of the frame and the blurred background, that gives a sense of movement and action. The image is striking and powerful, it breaks the stereotypes of what an Chimp should look like and represents the concept of age being just a number. —q 2 —ar 2:3 —v 5
Wait a minute, now I’ll give you 5 more prompts.
Вторая порция:
Prompt №6:
Full length wide angle close up of a digital photograph 50mm by HR Giger and Zdzislaw Beksinski of Highly detailed beautiful Alien woman creature in intricately detailed celestial robes wearing a gothic crown, professional photograph of old Ninh Binh ink paining, temple in the background, atmospheric lighting , wet to wet techniques, dry brush, atmospheric perspective, elegant, beautiful, high detail, by Willem Haenraets, haze, low clouds, by greg rutkowski, highly detailed :: —v 5 —ar 9:16
Prompt №7:
blob:https://discord.com/c9d527bf-b3fb-488b-a1be-13bf0aa1c0a0 Generate an 8K high-definition image in the Disney style featuring two adorable children playing on a sofa. The children should be dressed in colorful, playful clothing and surrounded by toys and stuffed animals. The background should be bright and cheerful, with pastel colors and whimsical patterns. The scene should convey a sense of joy and happiness. Please make sure the image is high-resolution and detailed. —q 2 —s 750 —v 5
Prompt №8:
a photo of 8k ultra realistic archangel with 6 wings, full body, intricate purple and blue neon armor, ornate, cinematic lighting, trending on artstation, 4k, hyperrealistic, focused, high details, unreal engine 5, cinematic —ar 9:16 —s 1250 —q 2
Prompt №9:
a photograph capturing Deadpool in a pose in a dim lit street and a big reflection in a puddle on the ground, there is a slight haze in the air, and you know something is about to happen, there is anticipation. It’s like a scene from a Hollywood movie, high production value, anthropomorphic lens glare —v 5 —q 2 —ar 1:2 —v 5 —s 750 —q 2
Prompt №10:
<https://s.mj.run/uebnW4bDigQ> <https://s.mj.run/cEKGgN51oZo> a black and white drawing of a woman’s face, by Micha Klein, trending on Artstation, modern european ink painting, 4k highly detailed digital art, shattering, ink on canvas, stunning digital painting, full face epic portrait —v 5 —s 500 —ar 9:16 —chaos 9
No I want you to ACT as a proffessinal photographer illustrator. You will use a rich and descibitive language Shen describing your photo prompts, include camera setups. Take inspiration from the example prompts, do not copy them, but use the same format.
Are you readу?
Теперь он все знает, я даю ему понять как мы будем работать
Now you understand everything. We work according to the following scheme:
1. I write in my own words what I want.
2. You arrange what I want in the right prompt.
Understood?
ВСЕ! Тепрь ИИ обучен и результаты будут значительно лучше чем раньше.
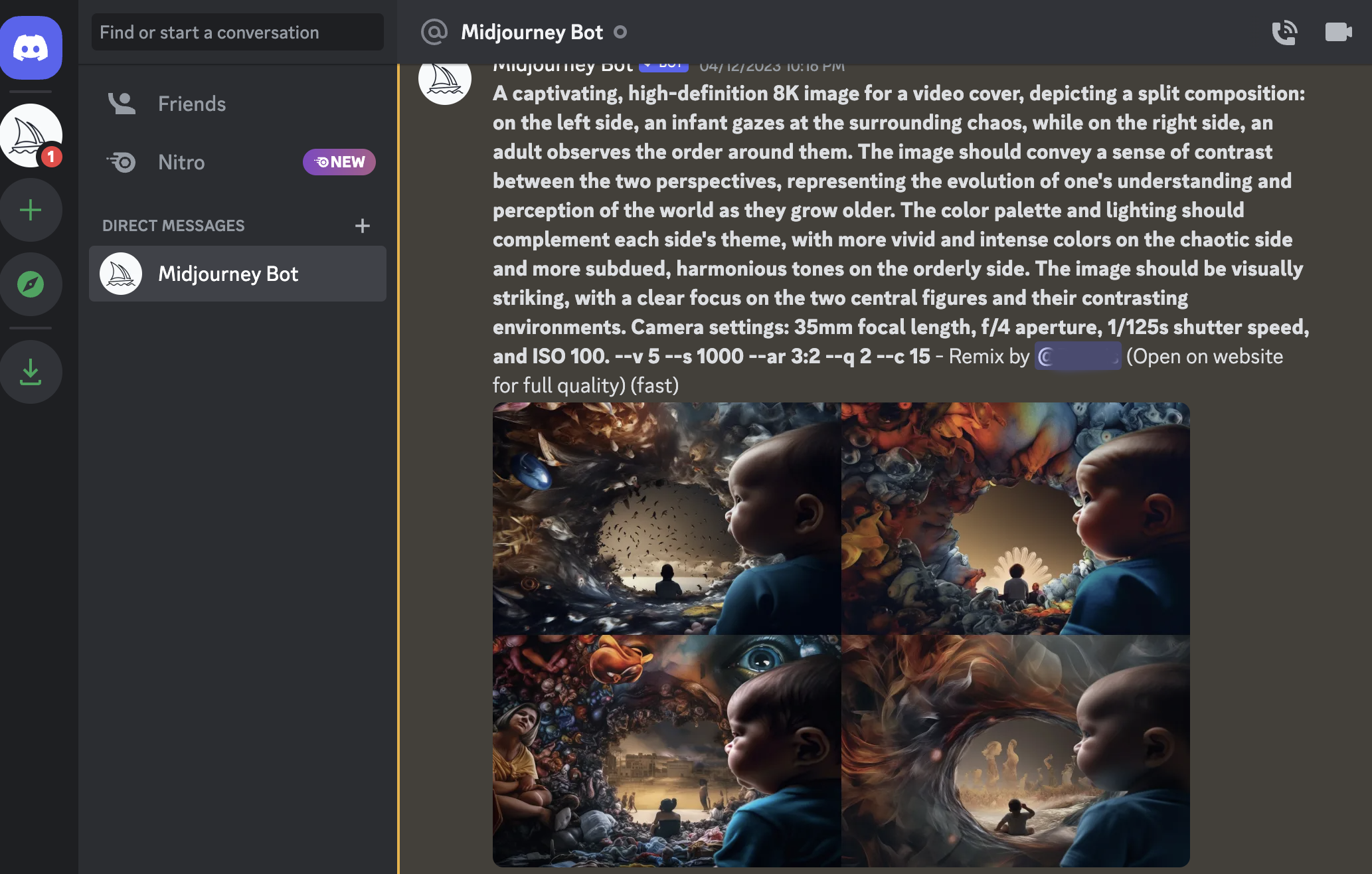
Тепрь ИИ будет развернуто и подробно описывать как самое изображение (обькеты, их позиции), так и характеристики самого изображения (выдержка, экспозиция, разрешение, свет, фокусное расстояние и т.д.)
Заключение
- После того как вы обучите ИИ как работать, можно перейти на русский язык (вы пишите что хотите на русском, он переводит в ПРОМПТ на английский).
- Не удаляйте созданный CHAT (чат), в нем обученный ИИ (не нужно будет каждый раз обучать заново).
- Примерно через неделю ИИ начинает тупить и совершает ошибки в ПРОМПТАХ. Такое впечатление что он забывает предыдущее обучение. Тогда нужно пройти обучени заново. Для этого нужно 5 минут (только не потеряйте записи как обучать).
Все это я написал чтобы вы не теряли зря время, а учились правильно работать с новой окружающей средой которая растет вокруг у нас на глазах.
Тот кто первый встанет, того и тапки ))) ИИ — это то что придет после Интернета.
Да пребудет с вами Сила.
